eBPF
BPF
Originally BPF was the abbreviation of Berkley Packet Processing, a small virtual machine running within the unix kernel designed to filter network packets on incoming interfaces. BPF allowed dynamic modifications of the filtering rules applied on the incoming packets giving power to the users for custom filtering criteria.
As technology progressed, particularly in the early 2010s, the Linux kernel became a dominant operating system for server-side computing. This stability led to challenges in innovating within the kernel without facing significant resistance. Key developers recognized limitations in the existing capabilities of the Linux kernel, regarding networking and observability, prompting them to extend BPF into what is now known as extended Berkley Packet Processing or eBPF. The term eBPF should not be treated as an abbreviation but rather as the name of the technology itself, as having the name extended Berkley Packet Processing does not name much sense anymore.
They did not need to start from scratch as Linux kernels already had orignal BPF support, so what was done is to just extend the virtual machine to support a wider instruction set with more general operations and turning it into a more generelized virtual machine running inside the kernel that could be used not only for packet filtering but for far more, especially observability, security and more custom packet processing.
eBPF
As mentioned eBPF is a virtual machine running inside the linux kernel. It has its own instruction set and registers. At the time of writing this article the eBPF VM has a total of 11 64bit general purpose registers named R0 up to R10, where different registers are used for different purposes following some specific conventions. The instruction set along with the meaning of each register can be looked up on kernel.org1 or simply by searching on the internet for eBPF instruction set.
The whole pipeline of executing eBPF programs is as follows, the eBPF program is written in the supported instruction set to achieve the desired behaviour, the program is then loaded into the kernel where it is verified before actually being executed. This step is important because running arbitrary programs inside the kernel is dangerous. Verification of the program is done by the verifier, which checks for every pointer access, infinite loops and generally prevents undefined behaviour that would crash the kernel. When loading arbitrary eBPF programs, the last thing we want is for the kernel to crash. Once the loading of the program passes the verification step, we have a guarantee that our program will not crash the kernel.
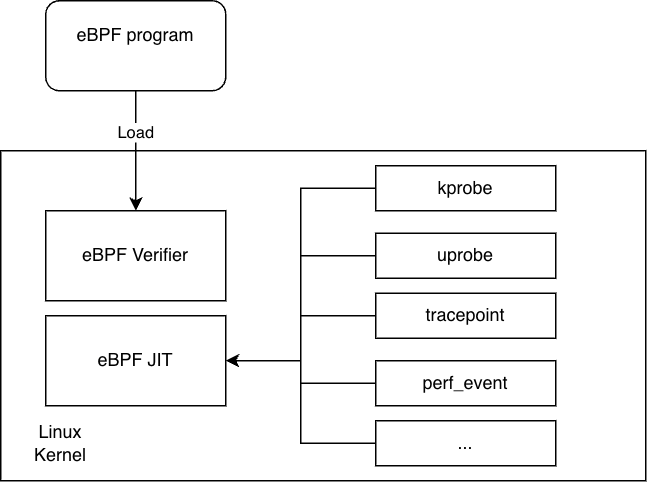
As you can see from the figure above, there are various events, namely kprobes, uprobes, tracepoints and perf events, to which the eBPF program can attach itself. Once the program is loaded into the kernel, it is not executed immediately, but on each occurrence of the given event.
In practice, eBPF programs are not written by hand with the instruction set (which is very similar to assembly), but there are already tools that we can use to speed up the development process. Clang is a C compiler based on LLVM that implements the BPF backend, meaning that we can write C code that we can then compile down to the instruction set of the eBPF virtual machine to run our programs. In addition, the eBPF ecosystem around the C language has a number of utilities that make working with eBPF much more pleasant, such as libbpf2.
Generally speaking, an eBPF binary, i.e. when the written program is compiled down to the VM executable, consists of more than just eBPF programs, there are also maps and also BTF (but more on that later). Maps are a way for eBPF programs to store state that can be carried over across multiple runs of the same program, or even to share data between different eBPF programs or even user space programs. As with the verifier, which would not allow arbitrary instructions to be executed within the kernel, maps also have a limitation in that they cannot hold infinite amounts of data, as we are used to when programming in userspace. Specific limits on the number of elements must be specified at compile time, and working with these limits will be one of the more difficult parts of writing eBPF programs, along with satisfying the verifier.
The main selling point of eBPF programs is that instead of writing kernel extensions, i.e. kernel modules, or recompiling the kernel with your own modifications, which could end up crashing the kernel if you are not very careful, you have this “safe” interface which can be used to deploy your modification much faster and safer.
Software development is an ongoing process that rarely, if ever, ends. As with previous options, such as the kernel module, the Linux kernel is constantly evolving, and type definitions within the kernel are subject to change in the future, directly affecting any custom extension we have provided for the current version. BPF programs are no exception.
When writing eBPF programs, you have access to the type definitions within the Linux kernel, which makes the development process much easier. When you develop the program, you compile it with respect to the current Linux version you are running, and thus with the kernel type definitions within that version, making it incompatible with newer or older kernel versions if the type definitions have changed. This is where Compile-Once Run-Everywhere (CO-RE) comes in.
CO-RE
If you wanted to deploy your program on multiple machines, you would most likely have compatibility problems unless each machine was running the exact same version of the Linux kernel. So, to solve this problem, you would have to download dependency and compilation tools on each machine, and then compile and deploy the eBPF program on each of them individually, ugh!
Not only is this cumbersome, it is also error-prone and wastes a lot of computing resources. Compile-Once Run-Everywhere addresses these compatibility issues between different Linux kernel versions for a compiled eBPF program by using BTF.
BTF is a mechanism that carries the type definitions, field offsets within types, function signatures, etc. for a specific Linux kernel version. This type information is then included in the compiled eBPF binary itself and when deployed, the inconsistencies are dynamically resolved at run time by the eBPF virtual machine without requiring any changes to the program, allowing you to compile your eBPF program once locally on your machine and deploy it to different machines. You will see an example of that in the Hello-World section.
Lifetime
BPF objects, maps, programs, etc. are managed by reference counting. Each time a map is created, its reference count is set to 1 and a file descriptor is returned to the calling user-space process. The returned file descriptor can then be used to interact with the map within the user-space process.
Similarly, when a bpf program is loaded, its reference count is set to 1 and a file descriptor is returned. Furthermore, when the bpf program uses a bpf map, the map is first created with a reference count of 1, and then increased again as the program itself references the map, resulting in the map remaining alive as long as the program is alive.
When the reference count for any bpf object reaches 0, it is aborted by the kernel and will not be executed again until it is loaded again.
In general, there are two ways to manage the lifecycle of an eBPF program. Run a user space process as long as the eBPF program needs to run, i.e. keep the file descriptor and thus the reference to the program/maps alive, or use pinning.
Pinning refers to a concept where we essentially “pin” the map or program to the file system and thus keep the reference to the bpf objects alive as long as the computer is running, and avoid problems with unwanted process terminations/restarts.
Hello World
Lets build a hello world eBPF program that prints every use of the openat syscall.
Setting up the development environment, by first downloading the necessary dependencies.
sudo apt install linux-headers-$(uname -r) \
libbpfcc-dev \
libbpf-dev \
llvm \
clang \
gcc-multilib \
build-essential \
linux-tools-$(uname -r) \
linux-tools-common \
linux-tools-generic
To work with the kernel data structures without running into various kinds of naming collisions when importing header files, btftool3 provides useful utilities for working with eBPF programs, including generating all the data structures used in the kernel, which we can then import into our eBPF program.
$ sudo bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
Next we find the trace hook for the openat syscall
$ sudo ls /sys/kernel/debug/tracing/events/syscalls/ | grep openat
>
sys_enter_openat
...
next, we figure out the arguments with passed to the syscall
sudo cat /sys/kernel/debug/tracing/events/syscalls/sys_enter_openat/format
name: sys_enter_openat
ID: 628
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:int __syscall_nr; offset:8; size:4; signed:1;
field:int dfd; offset:16; size:8; signed:0;
field:const char * filename; offset:24; size:8; signed:0;
field:int flags; offset:32; size:8; signed:0;
field:umode_t mode; offset:40; size:8; signed:0;
print fmt: "dfd: 0x%08lx, filename: 0x%08lx, flags: 0x%08lx, mode: 0x%08lx", ((unsigned long)(REC->dfd)), ((unsigned long)(REC->filename)), ((unsigned long)(REC->flags)), ((unsigned long)(REC->mode))
The program will have two parts, the kernel-space part and the user-space part. In order to exchange information between these two parts, a channel must be established with a common data structure that is known at compile time. We will create a file called events.h which will contain the necessary struct definitions, used by both parts of the program.
#ifndef EVENTS_H
#define EVENTS_H
#define MAX_COMM_LENGTH 32
struct event {
char parent_comm[MAX_COMM_LENGTH];
char requested_comm[MAX_COMM_LENGTH];
};
#endif
The next step is to write the kernel-space part of the eBPF program, the file will be named openatsnoop.bpf.c, note the .bpf to indicate that it is a bpf program written in C, not a regular user space program.
#include "vmlinux.h"
#include "events.h"
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 1024);
} buffer SEC(".maps");
char LICENSE[] SEC("license") = "GPL";
SEC("tracepoint/syscalls/sys_enter_openat")
int openat(struct trace_event_raw_sys_enter *ctx) {
struct event *event = bpf_ringbuf_reserve(&buffer, sizeof(struct event), 0);
if (!event) {
// failed to allocate memory for next event.
return 0;
}
bpf_get_current_comm(&event->parent_comm, sizeof(event->parent_comm));
bpf_probe_read_str(&event->requested_comm, sizeof(event->requested_comm), (void*)ctx->args[1]);
bpf_ringbuf_submit(event, 0);
return 0;
}
NOTE: The SEC macros you see will be translated to sections in the compiled binary itself (we will come back to this later), we can use these sections to identify which bpf objects are present in the binary.
- The program starts by including the generated “vmlinux.h” will all necessary kernel data structures which we then reference in the eBPF program.
-
We define a map called
bufferand give it a maximum of 1024 elements. Its type isBPF_MAP_TYPE_RINGBUF, which is a common mechanism to exchange data between the kernel and user-space part of the eBPF program. A ring buffer is a circular buffer where data is pushed and consumed from.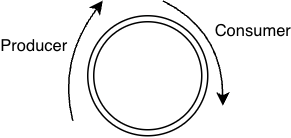
In this case the kernel part would be the producer and the user-space part the consumer of the ring buffer.
-
The license. Your eBPF program must specify a license. This depends on what your program needs to achieve and whether it needs the helper functions defined in the bpf library itself or not. If you use a GPL-licensed helper function, then your eBPF program itself must use the GPL license.
-
Finally, the eBPF program itself, which is attached to the
sys_enter_openatsyscall. The program itself is quite simple, we reserve memory in the ring buffer and then read the process name that is executing thesys_enter_openatsyscall withbpf_get_current_comm(&event->parent_comm, sizeof(event->parent_comm))and the filename that is passed to the syscall as an argument withbpf_probe_read_str(&event->requested_comm, sizeof(event->requested_comm), (void*)ctx->args[1]). We then pass this data to the ring buffer to be processed in the user-space part of the eBPF program.NOTE that the filename is the second argument passed to the syscall, which we can also identify from the above information about the syscall dumped via
sudo cat /sys/kernel/debug/tracing/events/syscalls/sys_enter_openat/format, thusctx->args[1]is used within the eBPF program.
Before we get to the user-space part of the program, a few more steps will be discussed. Now that we have completed the kernel-space part, we can compile it down to the eBPF binary that can be run on the virtual machine. To do this, as mentioned before, we use clang.
clang -target bpf -c openatsnoop.bpf.c -O2 -g
-target bpfspecifies the target architecture to which the program will compile to.-cOnly run preprocess, compile, and assemble steps.-O2is the optimization level.-gtells clang to compile with debug information. This include the BTF information in the binary to be used with CO-RE.
If we now inspect the generated binary, named openatsnoop.bpf.o
readelf -S openatsnoop.bpf.o
There are 27 section headers, starting at offset 0x14b0:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .strtab STRTAB 0000000000000000 00001383
000000000000012b 0000000000000000 0 0 1
[ 2] .text PROGBITS 0000000000000000 00000040
0000000000000000 0000000000000000 AX 0 0 4
[ 3] tracepoint/s[...] PROGBITS 0000000000000000 00000040
00000000000000a8 0000000000000000 AX 0 0 8
[ 4] .reltracepoi[...] REL 0000000000000000 00000f40
0000000000000010 0000000000000010 I 26 3 8
[ 5] license PROGBITS 0000000000000000 000000e8
0000000000000004 0000000000000000 WA 0 0 1
[ 6] .maps PROGBITS 0000000000000000 000000f0
0000000000000010 0000000000000000 WA 0 0 8
[ 7] .debug_loclists PROGBITS 0000000000000000 00000100
0000000000000027 0000000000000000 0 0 1
[ 8] .debug_abbrev PROGBITS 0000000000000000 00000127
000000000000011e 0000000000000000 0 0 1
[ 9] .debug_info PROGBITS 0000000000000000 00000245
0000000000000217 0000000000000000 0 0 1
[10] .rel.debug_info REL 0000000000000000 00000f50
0000000000000050 0000000000000010 I 26 9 8
[11] .debug_str_o[...] PROGBITS 0000000000000000 0000045c
0000000000000098 0000000000000000 0 0 1
[12] .rel.debug_s[...] REL 0000000000000000 00000fa0
0000000000000240 0000000000000010 I 26 11 8
[13] .debug_str PROGBITS 0000000000000000 000004f4
00000000000001c0 0000000000000001 MS 0 0 1
[14] .debug_addr PROGBITS 0000000000000000 000006b4
0000000000000020 0000000000000000 0 0 1
[15] .rel.debug_addr REL 0000000000000000 000011e0
0000000000000030 0000000000000010 I 26 14 8
[16] .BTF PROGBITS 0000000000000000 000006d4
00000000000004c2 0000000000000000 0 0 4
[17] .rel.BTF REL 0000000000000000 00001210
0000000000000020 0000000000000010 I 26 16 8
[18] .BTF.ext PROGBITS 0000000000000000 00000b98
00000000000000ec 0000000000000000 0 0 4
[19] .rel.BTF.ext REL 0000000000000000 00001230
00000000000000b0 0000000000000010 I 26 18 8
[20] .debug_frame PROGBITS 0000000000000000 00000c88
0000000000000028 0000000000000000 0 0 8
[21] .rel.debug_frame REL 0000000000000000 000012e0
0000000000000020 0000000000000010 I 26 20 8
[22] .debug_line PROGBITS 0000000000000000 00000cb0
00000000000000b8 0000000000000000 0 0 1
[23] .rel.debug_line REL 0000000000000000 00001300
0000000000000080 0000000000000010 I 26 22 8
[24] .debug_line_str PROGBITS 0000000000000000 00000d68
000000000000006c 0000000000000001 MS 0 0 1
[25] .llvm_addrsig LOOS+0xfff4c03 0000000000000000 00001380
0000000000000003 0000000000000000 E 26 0 1
[26] .symtab SYMTAB 0000000000000000 00000dd8
0000000000000168 0000000000000018 1 12 8
We can see all the sections we specified in the eBPF program with the SEC macros, along with the generated BTF information under the .BTF section. But as you can see, there is also other debug information generated by clang that we do not need, so we can simply get rid of it by using llvm-strip -g openatsnoop.bpf.o.
readelf -S openatsnoop.bpf.o
There are 13 section headers, starting at offset 0x8b0:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .strtab STRTAB 0000000000000000 00000823
0000000000000088 0000000000000000 0 0 1
[ 2] .text PROGBITS 0000000000000000 00000040
0000000000000000 0000000000000000 AX 0 0 4
[ 3] tracepoint/s[...] PROGBITS 0000000000000000 00000040
00000000000000a8 0000000000000000 AX 0 0 8
[ 4] .reltracepoi[...] REL 0000000000000000 00000740
0000000000000010 0000000000000010 I 12 3 8
[ 5] license PROGBITS 0000000000000000 000000e8
0000000000000004 0000000000000000 WA 0 0 1
[ 6] .maps PROGBITS 0000000000000000 000000f0
0000000000000010 0000000000000000 WA 0 0 8
[ 7] .BTF PROGBITS 0000000000000000 00000100
00000000000004c2 0000000000000000 0 0 4
[ 8] .rel.BTF REL 0000000000000000 00000750
0000000000000020 0000000000000010 I 12 7 8
[ 9] .BTF.ext PROGBITS 0000000000000000 000005c4
00000000000000ec 0000000000000000 0 0 4
[10] .rel.BTF.ext REL 0000000000000000 00000770
00000000000000b0 0000000000000010 I 12 9 8
[11] .llvm_addrsig LOOS+0xfff4c03 0000000000000000 00000820
0000000000000003 0000000000000000 E 0 0 1
[12] .symtab SYMTAB 0000000000000000 000006b0
0000000000000090 0000000000000018 1 3 8
Now we only have the necessary sections present for the eBPF program to be loaded into kernel, we can write the user-space part of the program. Working with eBPF programs from the user-space is sometimes repetetive and alot of boilerplate code needs to be written. Luckily, bpftool provides us with a lot of usefull commands to work with eBPF programs, one of which is to dump a C header file which we then can import in our user-space program that takes care of alot of the boilerplate. To achieve this we execute the command
sudo bpftool gen skeleton openatsnoop.bpf.o > openatsnoop.skel.h
Now we have everything ready and can start writing the user-space program.
#include "openatsnoop.skel.h"
#include "events.h"
#include <stdio.h>
// print function to be registered with the libbpf library, which will print out information when the eBPF
// binary `openatsnoop.bpf.o` is loaded into the kernel.
int debug_print(enum libbpf_print_level level, const char *format, va_list args) { return vfprintf(stdout, format, args); }
// callback function used with the created ring buffer to consume messages send from the kernel-space
// and print them out to stdout in the user-space.
int handle_event(void *ctx, void *data, size_t size) {
struct event *event = data;
fprintf(stdout, "%s openat: %s\n", event->parent_comm, event->requested_comm);
return 0;
}
int main(int argc, char **arv) {
int err = 0;
struct ring_buffer *buffer = NULL;
// Defined in the generated boilerplate `openatsnoop.skel.h`.
// This generate skeleton boilerplate will contain all the necessary references and
// file descriptors to all bpf objects defined in the compiled eBPF binary, along
// with utility functions to will ease the process.
struct hello_world_bpf *skeleton = NULL;
// register print function.
libbpf_set_print(debug_print);
// open the binary and immediately load it into the kernel.
skeleton = hello_world_bpf__open_and_load();
if (!skeleton) {
goto done;
}
// at this point the eBPF program was successfully verified and is loaded in the kernel
// however we still need to attach is to the requested tracepoint event.
err = hello_world_bpf__attach(skeleton);
if (err) {
goto done;
}
// we create a reference to the ring buffer map created by the eBPF program and use
// the file descriptor that can be retrieved with the `bpf_map__fd()` function from
// the libbpf library, and attach a function to be triggered when the kernel-space
// programs submits new data to be consumed.
buffer = ring_buffer__new(bpf_map__fd(skeleton->maps.buffer), handle_event, 0, 0);
if (!buffer) {
goto done;
}
for (;;) {
// check for new data in the ring buffer every 10ms.
err = ring_buffer__poll(buffer, 10);
if (err < 0) {
break;
}
}
done:
if (skeleton) hello_world_bpf__destroy(skeleton);
if (buffer) ring_buffer__free(buffer);
return -err;
}
Since the generated template file is quite large, I have decided not to show the contents of this file, but it is possible to view it on github
Now we have all the files present and your directory should look like this
.
|---- events.h
|---- openatsnoop.bpf.c
|---- openatsnoop.bpf.o
|---- openatsnoop.skel.h
|---- openatsnoop.c
|---- vmlinux.h
Finally, to compile the user-space program and run it
# on my machine the libbpf is under /usr/lib64/ this may difer for you.
$ clang openatsnoop.c -L/usr/lib64/ -lbpf -lelf -Wl, -rpath /usr/lib64/
$ sudo ./a.out
libbpf: loading object 'hello_world_bpf' from buffer
libbpf: elf: section(3) tracepoint/syscalls/sys_enter_openat, size 168, link 0, flags 6, type=1
libbpf: sec 'tracepoint/syscalls/sys_enter_openat': found program 'openat' at insn offset 0 (0 bytes), code size 21 insns (168 bytes)
libbpf: elf: section(4) .reltracepoint/syscalls/sys_enter_openat, size 16, link 12, flags 40, type=9
libbpf: elf: section(5) license, size 4, link 0, flags 3, type=1
libbpf: license of hello_world_bpf is GPL
libbpf: elf: section(6) .maps, size 16, link 0, flags 3, type=1
libbpf: elf: section(7) .BTF, size 1218, link 0, flags 0, type=1
libbpf: elf: section(9) .BTF.ext, size 236, link 0, flags 0, type=1
libbpf: elf: section(12) .symtab, size 144, link 1, flags 0, type=2
libbpf: looking for externs among 6 symbols...
libbpf: collected 0 externs total
libbpf: map 'buffer': at sec_idx 6, offset 0.
libbpf: map 'buffer': found type = 27.
libbpf: map 'buffer': found max_entries = 1024.
libbpf: sec '.reltracepoint/syscalls/sys_enter_openat': collecting relocation for section(3) 'tracepoint/syscalls/sys_enter_openat'
libbpf: sec '.reltracepoint/syscalls/sys_enter_openat': relo #0: insn #1 against 'buffer'
libbpf: prog 'openat': found map 0 (buffer, sec 6, off 0) for insn #1
libbpf: object 'hello_world_bpf': failed (-22) to create BPF token from '/sys/fs/bpf', skipping optional step...
libbpf: loaded kernel BTF from '/sys/kernel/btf/vmlinux'
libbpf: sec 'tracepoint/syscalls/sys_enter_openat': found 1 CO-RE relocations
libbpf: CO-RE relocating [10] struct trace_event_raw_sys_enter: found target candidate [2380] struct trace_event_raw_sys_enter in [vmlinux]
libbpf: prog 'openat': relo #0: <byte_off> [10] struct trace_event_raw_sys_enter.args[1] (0:2:1 @ offset 24)
libbpf: prog 'openat': relo #0: matching candidate #0 <byte_off> [2380] struct trace_event_raw_sys_enter.args[1] (0:2:1 @ offset 24)
libbpf: prog 'openat': relo #0: patched insn #11 (LDX/ST/STX) off 24 -> 24
libbpf: map 'buffer': created successfully, fd=3
systemd-oomd openat: /proc/meminfo
systemd-oomd openat: /proc/meminfo
systemd-oomd openat: /proc/meminfo
systemd-oomd openat: /sys/fs/cgroup/user.slice/user-
systemd-oomd openat: /sys/fs/cgroup/user.slice/user-
systemd-oomd openat: /sys/fs/cgroup/user.slice/user-
systemd-oomd openat: /sys/fs/cgroup/user.slice/user-
systemd-oomd openat: /sys/fs/cgroup/user.slice/user-
systemd-oomd openat: /sys/fs/cgroup/user.slice/user-
systemd-oomd openat: /proc/meminfo
systemd-oomd openat: /proc/meminfo
systemd-oomd openat: /proc/meminfo
systemd-oomd openat: /proc/meminfo
systemd-oomd openat: /proc/meminfo
systemd-oomd openat: /sys/fs/cgroup/user.slice/user-
systemd-oomd openat: /sys/fs/cgroup/user.slice/user-
systemd-oomd openat: /sys/fs/cgroup/user.slice/user-
systemd-oomd openat: /sys/fs/cgroup/user.slice/user-
systemd-oomd openat: /sys/fs/cgroup/user.slice/user-
systemd-oomd openat: /sys/fs/cgroup/user.slice/user-
systemd-oomd openat: /proc/meminfo
NOTE You can also see the relocation happening as the eBPF binary is loaded with the CO-RE.
The reference for the code is available on github
XDP - Hello World
One of the most important features of eBPF is the introduction of the eXpress Data Path hook, or XDP for short. To give a brief history of why this was implemented, let us look at the state of packet processing in the Linux kernel.
When a packet arrives on the network interface card hardware, it is processed by the software device drivers. This processing involves the creation of a structure called sk_buff, which is the in kernel representation of the packet, which is then processed by the networking stack in the kernel. Creating the sk_buff structure involves copying data and can introduce performance bottlenecks.
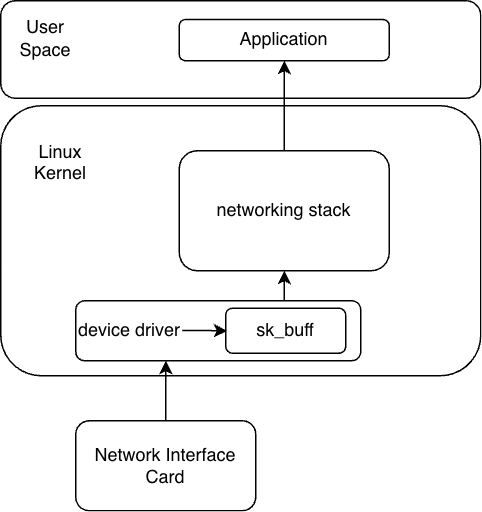
There are already solutions for bypassing the Linux networking stack by working directly with network interfaces, such as a DPDK4 that allows you to bypass the kernel altogether and pass control of packet handling to the networking application itself. The downside of such solutions is that they lose access to the existing networking features of the Linux kernel, such as routing tables or the tcp stack, and may need to implement their own solution.
Now, what XDP allows us to do is, to hook our eBPF programs directly to the network interface card drivers, if the drivers support it, and process the packets immediately as they arrive at the interface, before the sk_buff structure is created. XDP allows us to perform inspections or modifications on the packet itself, including deciding to drop or redirect the packet. XDP programs are triggered on every single incoming packet on the interface on which the program is attached to.
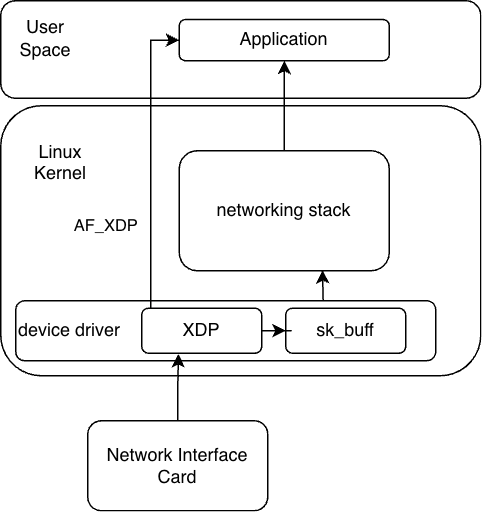
To also demonstrate a hello-world program similar to the above one lets write a XDP program that attaches to the main eth interface and on every incoming packets prints the source address, either ipv4 or ipv6.
We will use just a single file called sourceip.bpf.c and will utilize the iproute2 command line tools to attach the eBPF program to an existing interface.
NOTE: that when we attach an XDP program to an interface the program will live as long as that interface exists or until the program is dettached again, as the reference count will be above 0.
#include <linux/if_ether.h>
#include <linux/if_packet.h>
#include <bpf/bpf_endian.h>
#include <linux/ip.h>
#include <linux/ipv6.h>
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
char LICENSE[] SEC("license") = "GPL";
SEC("xdp")
int sourceip(struct xdp_md *ctx) {
void* start = (void*)(long)ctx->data;
void* end = (void*)(long)ctx->data_end;
// first convert to ethernet header.
struct ethhdr *eth = start;
int ethsize = sizeof(struct ethhdr);
if (start + ethsize > end) {
return XDP_PASS;
}
if (eth->h_proto == bpf_htons(ETH_P_IP)) {
struct iphdr *ip = (start + ethsize);
int ipsize = sizeof(struct iphdr);
if (start + ethsize + ipsize > end) {
return XDP_PASS;
}
bpf_printk("Received Source IP: %d.%d.%d.%d\n",
(ip->saddr & 0xFF),
(ip->saddr >> 8) & 0xFF,
(ip->saddr >> 16) & 0xFF,
(ip->saddr >> 24) & 0xFF
);
} else {
struct ipv6hdr *ipv6 = (start + ethsize);
int ipsize = sizeof(struct ipv6hdr);
if (start + ethsize + ipsize > end) {
return XDP_PASS;
}
bpf_printk("Recieved Source IPv6: %04x:%04x:%04x:%04x:%04x:%04x:%04x:%04x",
(ipv6->saddr.in6_u.u6_addr16[0]),
(ipv6->saddr.in6_u.u6_addr16[1]),
(ipv6->saddr.in6_u.u6_addr16[2]),
(ipv6->saddr.in6_u.u6_addr16[3]),
(ipv6->saddr.in6_u.u6_addr16[4]),
(ipv6->saddr.in6_u.u6_addr16[5]),
(ipv6->saddr.in6_u.u6_addr16[6]),
(ipv6->saddr.in6_u.u6_addr16[7])
);
}
// continue with the linux network stack.
// other options are:
//
// XDP_ABORTED,
// XDP_DROP,
// XDP_PASS,
// XDP_TX,
// XDP_REDIRECT,
return XDP_PASS;
}
Next we compile it down to the eBPF binary
A = $(shell uname -m)
ARCH = $(shell uname -m | sed 's/x86_64/x86/' | sed 's/aarch64/arm64/')
clang -target bpf -c sourceip.bpf.c -g -O2 -Wall -D __TARGET_ARCH_$(ARCH) -I/usr/include/$(A)-linux-gnu
llvm-strip -g sourceip.bpf.o
NOTE: you may run into issues with /usr/include/linux/if_packet.h:5:10: fatal error: 'asm/byteorder.h' file not found, thats why the extra compiler flags.
We list the interfaces present on this machine and attach the eBPF program to the enp0s1 interface.
ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp0s1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 6a:eb:5b:1c:62:51 brd ff:ff:ff:ff:ff:ff
sudo ip link set dev enp0s1 xdp obj sourceip.bpf.o sec xdp
#to turn it off -> sudo ip link set dev enp0s1 xdp off
Since we did not explicitly use a userspace part for the eBPF program to collect the source IPs of incoming packets, and decided to use the built-in bpf_printk function, to view the output we need to run the following command to view the logs
sudo cat /sys/kernel/debug/tracing/trace_pipe
If you now ping the interface on which the XDP program is attached, e.g on my machine ping 192.168.72.1 you should see the source address being printed.
<idle>-0 [000] ..s2. 49853.931760: bpf_trace_printk: Received Source IP: 192.168.72.1
<idle>-0 [000] ..s2. 49854.984813: bpf_trace_printk: Received Source IP: 192.168.72.1
<idle>-0 [000] ..s2. 49856.010607: bpf_trace_printk: Received Source IP: 192.168.72.1
<idle>-0 [000] ..s2. 49857.012974: bpf_trace_printk: Received Source IP: 192.168.72.1
<idle>-0 [000] ..s2. 49858.013830: bpf_trace_printk: Received Source IP: 192.168.72.1
NOTE: the /sys/kernel/debug/tracing/trace_pipe is a common pipe for all eBPF programs and should not be used in any production software.
The code for this example is published on github. A good tutorial on XDP, from basics to advanced, can be found at xdp-project
Future
So what does the future hold for eBPF? The technology is still evolving and far from finished. New possibilities are constantly being worked on, such as GPU support, evolving networking in the cloud environment, such as the company Isovalent with their Cilium network solution based on eBPF, or even moving to different platforms, recently Microsoft announced that they will adopt eBPF for windows5.
Conclusion
Bpf has proven to be a game-changing technology by companies like Isovalent, drastically improving network latency within Kubernetes clusters and becoming the de facto standard goto network plugin used by various companies. It’s hard to predict the future, but at the time of writing, it’s safe to say that eBPF is here to stay and will only get better from here.
Footnotes